TiDB 几个关键点探究
背景
各路Newsql数据库做的越来越好, 在未来数字化道路上,数据库作为最基本的组成要素,该如何决策? 是继续跑在IOE上,大把大把烧钞票来维系着高可用? 还是用日渐成熟的互联网开源武器武装自己。这是个关于钱和事的大问题。
我提倡的策略是 积极试用,谨慎展开。分级替换,评估成本。
当前M平台每日入库数据在500万-700万条,不久会增加到至少1000万条/日。 而且数据实时计算要求越来越高,怎么办?
2020-02-16 5,546,434 records
2020-02-15 6,498,376 records
2020-02-14 5,227,550 records
如果不花大把银子(部署Exadata), 用普通Oracle,Mysql,postgreSQL架构是不容易搞定这个场景要求的。
当下各种NewSQL都开始商业化试用,特别是各类基于 MySQL 生态和兼容 MySQL 协议的新数据库产品,包括在 OLTP 上进一步优化的 POLARDB(2.0支持Oracle 规范)、Aurora、X-DB等等,还有兼容 OLTP 和 OLAP 场景的 HTAP 上优化的 HybridDB、TiDB、BaikalDB 等等。 重点可以关注POLARDB和TiDB(当前仅支持Mysql规范)。
TiDB几个核心的点
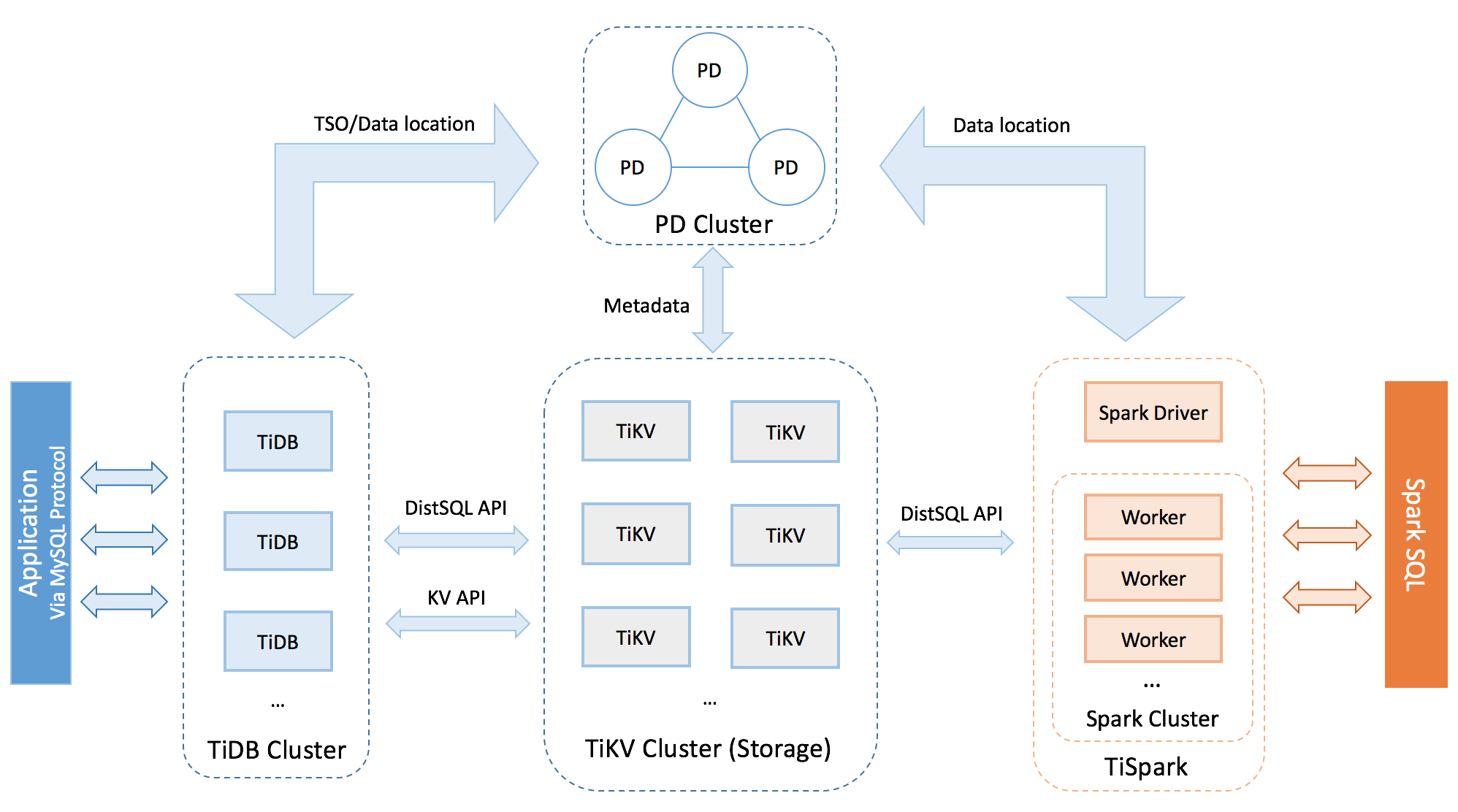
TiDB Server
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果。TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如LVS、HAProxy 或 F5)对外提供统一的接入地址。
PD Server(借力etcd Raft)
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个:一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);三是分配全局唯一且递增的事务 ID。
PD 通过 Raft 协议保证数据的安全性。Raft 的 leader server 负责处理所有操作,其余的 PD server 仅用于保证高可用。建议部署奇数个 PD 节点。
TiKV Server(借力RocksDB)
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。
TiSpark (借力Spark)
TiSpark 作为 TiDB 中解决用户复杂 OLAP 需求的主要组件,将 Spark SQL 直接运行在 TiDB 存储层上,同时融合 TiKV 分布式集群的优势,并融入大数据社区生态。至此,TiDB 可以通过一套系统,同时支持 OLTP 与 OLAP,免除用户数据同步的烦恼。
TiDB Operator
TiDB Operator 提供在主流云基础设施(Kubernetes)上部署管理 TiDB 集群的能力。它结合云原生社区的容器编排最佳实践与 TiDB 的专业运维知识,集成一键部署、多集群混部、自动运维、故障自愈等能力,极大地降低了用户使用和管理 TiDB 的门槛与成本。
第一个关键点:RocksDB
TiDB的说法:
任何持久化的存储引擎,数据终归要保存在磁盘上,TiKV 也不例外。但是 TiKV 没有选择直接向磁盘上写数据,而是把数据保存在 RocksDB 中,具体的数据落地由 RocksDB 负责。
Facebook 这个项目是比较有意思的,个人觉得比PolarDB里那个阿里搞的PolarFS有趣。
RocksDB是使用C++编写的嵌入式kv存储引擎,其键值均允许使用二进制流。由Facebook基于levelDB开发, 提供向后兼容的levelDB API。
RocksDB针对Flash存储进行优化,延迟极小。RocksDB使用LSM存储引擎,纯C++编写。Java版本RocksJava正在开发中。参见RocksJavaBasic。
RocksDB依靠大量灵活的配置,使之能针对不同的生产环境进行调优,包括直接使用内存,使用Flash,使用硬盘或者HDFS。支持使用不同的压缩算法,并且有一套完整的工具供生产和调试使用。
功能
- 为需要存储TB级别数据到本地FLASH或者RAM的应用服务器设计
- 针对存储在高速设备的中小键值进行优化——你可以存储在flash或者直接存储在内存
- 性能碎CPU数量线性提升,对多核系统友好
LevelDB所没有的功能
RocksDB增加了许多新功能,参考features not in LevelDB
没有这么简单,TiDB实际上有个项目在https://tikv.org/ 这才是TiKV正主,虽然是系出RocksDB。
TiKV is implemented in the Rust programming language. It uses technologies like Facebook’s RocksDB and Raft.
The project was originally inspired by Google Spanner and HBase.
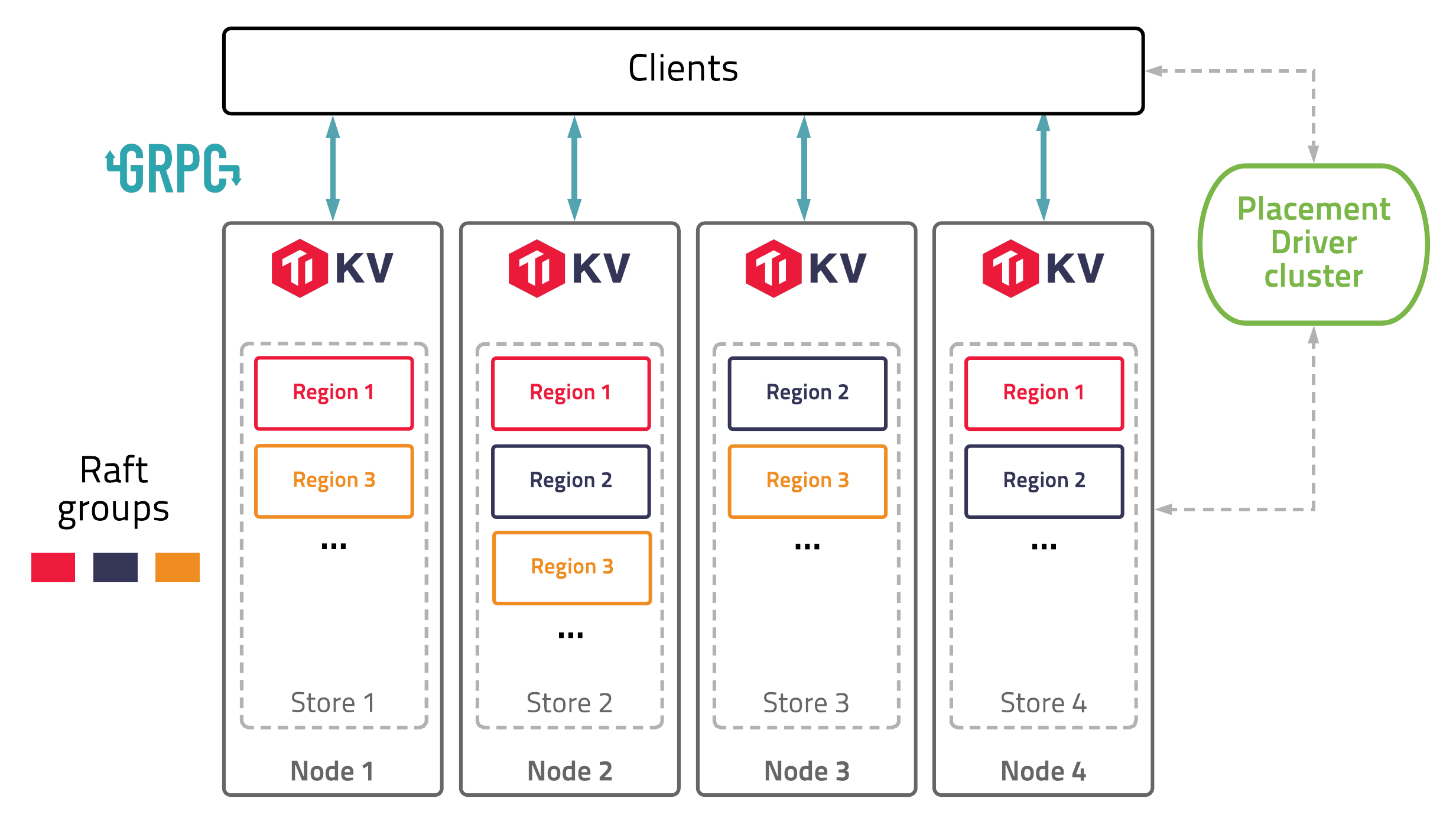
第二个关键点:Raft
TiDB的说法:
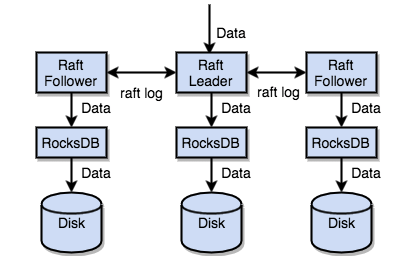
一件更难的事情:如何保证单机失效的情况下,数据不丢失,不出错?简单来说,我们需要想办法把数据复制到多台机器上,这样一台机器挂了,我们还有其他的机器上的副本;复杂来说,我们还需要这个复制方案是可靠、高效并且能处理副本失效的情况。听上去比较难,但是好在我们有 Raft 协议。Raft 是一个一致性算法,它和 Paxos 等价,但是更加易于理解。这里是 Raft 的论文,感兴趣的可以看一下。本文只会对 Raft 做一个简要的介绍,细节问题可以参考论文。另外提一点,Raft 论文只是一个基本方案,严格按照论文实现,性能会很差,我们对 Raft 协议的实现做了大量的优化,具体的优化细节可参考我司首席架构师唐刘同学的这篇文章。
Raft 是一个一致性协议,提供几个重要的功能:
- Leader 选举
- 成员变更
- 日志复制
TiKV 利用 Raft 来做数据复制,每个数据变更都会落地为一条 Raft 日志,通过 Raft 的日志复制功能,将数据安全可靠地同步到 Group 的多数节点中。
我们进一步看看:
本质上来说TiDB 采用的是etcd Raft,Distributed reliable key-value store for the most critical data of a distributed system https://etcd.io 这个方案, 其中引入包情况如下:
"go.etcd.io/etcd/clientv3"
"go.etcd.io/etcd/embed"
"go.etcd.io/etcd/pkg/types"参考一下阿里云的Polardb架构,他们用Parallel-Raft协议保证数据的一致性,这块闭源, 具体了解可以参考阿里在PVLDB的一篇论文《PolarFS: An Ultra-low Latency and Failure Resilient Distributed File System for Shared Storage Cloud Database》,其中介绍了一种比Raft更高效的一致性协议ParallelRaft,号称可以支持乱序提交。从ParallelRaft看得出阿里工程能力挺强。
Raft是一个比Paxos更易于理解与实现的一致性协议(consensus protocol),详细介绍参考Raft协议详解和分布式系统的Raft算法。 来自参考文章。
再去看TiDB的Region Syncer,pd/server/region_syncer/server.go
// RegionSyncer is used to sync the region information without raft.
type RegionSyncer struct {
sync.RWMutex
streams map[string]ServerStream
regionSyncerCtx context.Context
regionSyncerCancel context.CancelFunc
server Server
closed chan struct{}
wg sync.WaitGroup
history *historyBuffer
limit *ratelimit.Bucket
securityConfig *grpcutil.SecurityConfig
}
// NewRegionSyncer returns a region syncer.
// The final consistency is ensured by the heartbeat.
// Strong consistency is not guaranteed.
// Usually open the region syncer in huge cluster and the server
// no longer etcd but go-leveldb.
func NewRegionSyncer(s Server) *RegionSyncer {
return &RegionSyncer{
streams: make(map[string]ServerStream),
server: s,
closed: make(chan struct{}),
history: newHistoryBuffer(defaultHistoryBufferSize, s.GetStorage().GetRegionStorage()),
limit: ratelimit.NewBucketWithRate(defaultBucketRate, defaultBucketCapacity),
securityConfig: s.GetSecurityConfig(),
}
}所以可以看到Region的Sync是采用了go-leveldb而非etcd。这是为啥呢? 其实吧,LeveldbKV is used to store regions information. // RegionSyncer is used to sync the region information without raft.
"github.com/syndtr/goleveldb/leveldb"
"github.com/syndtr/goleveldb/leveldb/util"具体参见 https://github.com/syndtr/goleveldb PingCAP的人好爱用levelDB。难道是因为LevelDB 是基于内存 + SSD的冷热分离架构。
你能看到这,说明你还是很有耐心的,TiDB是很有前途的NewSQL数据库,真心希望他们走的越来越好。早早兼容Oracle语法。当好去IOE排头兵。