
在Meta,内部数据工具是数据科学家到生产工程师的主要渠道。因此,对我们来说,让我们的科学家和工程师不仅能够利用数据做出决策,而且能够以安全和合规的方式做出决策,这一点非常重要。
我们已经开发了SQL Notebooks,一个结合了SQL IDEs和Jupyter Notebooks的力量的新工具。它允许基于SQL的分析以比传统笔记本更可扩展和安全的方式进行,同时仍然提供来自笔记本和基本[SQL编辑]的功能,如多个相互依赖的单元和Python后处理。
在推出后的一年里,SQL笔记本已经被Meta公司的大多数数据科学家和数据工程师内部采用。以下是我们如何将两个普遍存在的工具结合起来,创造出比其各部分之和更大的东西。
SQL+Python效果就像“槟榔加烟,法力无边”, 当然不会有那么大的毒害。
SQL的优势
人们访问数据的方式有很多。它可以通过像 Scuba这样的用户界面,像我们的 时间序列数据库这样的特定领域语言(DSL),或者像Spark的Scala这样的程序化API。然而,访问分析数据的主要方式是良好的旧SQL。这包括对我们主要分析数据库的大多数查询。Presto、Spark和MySQL数据库。
从早期开始,我们就有了内部工具,通过网络界面的SQL来查询分布式数据库的数据。第一个版本称为HiPal(Hive + Pal),从Hive数据库中查询数据,并继续激发了开源工具[Airpal](http://airbnb.io/airpal/)。HiPal后来被一个更通用的工具Daiquery取代,它可以查询任何基于SQL的数据存储,包括Presto、Spark、MySQL和Oracle,并提供开箱即用的可视化。
Daiquery是许多经常与SQL互动的人的首选工具,Meta公司90%的数据科学家和工程师都在使用。
笔记本的力量和局限性
Jupyter笔记本一直是数据科学家的一个革命性的工具。它通过支持多个单元格和内联标记,实现了丰富的可视化和步进式文档。在Meta,我们已经通过一个名为 Bento的项目将笔记本与我们的生态系统整合在一起。
然而,虽然笔记本的功能非常强大,但也有一些限制。
可扩展性。由于进程在本地运行,它在内存和CPU方面受到单台机器的限制,这妨碍了处理大数据,JupyterHub 虽然可以实现,但是依然很多问题。
报告和共享。由于笔记本与单台机器相关联,与其他人共享任何快照结果需要与整个笔记本一起保存。
这种方法有两个主要缺点。
- 安全:底层数据可能有ACL检查(例如,在表层)。这对于快照来说是很难执行的,因为这需要执行代码,而且如果笔记本的所有者对访问控制不是很勤奋,可能会导致数据泄露。
- 稳定性:因为这是数据的快照,除非有人定期运行笔记本,否则它不会更新,这可能导致误导性的结果或需要笔记本作者定期进行人工干预。
进入SQL笔记本
SQL Notebooks 集笔记本和 SQL 编辑器的优点于一身。以下是使SQL Notebooks强大的一些功能:
###模块化SQL
我们经常收到这样的反馈:SQL可能会变得非常复杂和难以维护。像Presto这样的数据库支持通用表表达式(CTE),这对代码组织有很大的帮助。然而,并不是每个人都熟悉CTE,有时很难执行良好的做法,使代码可读。
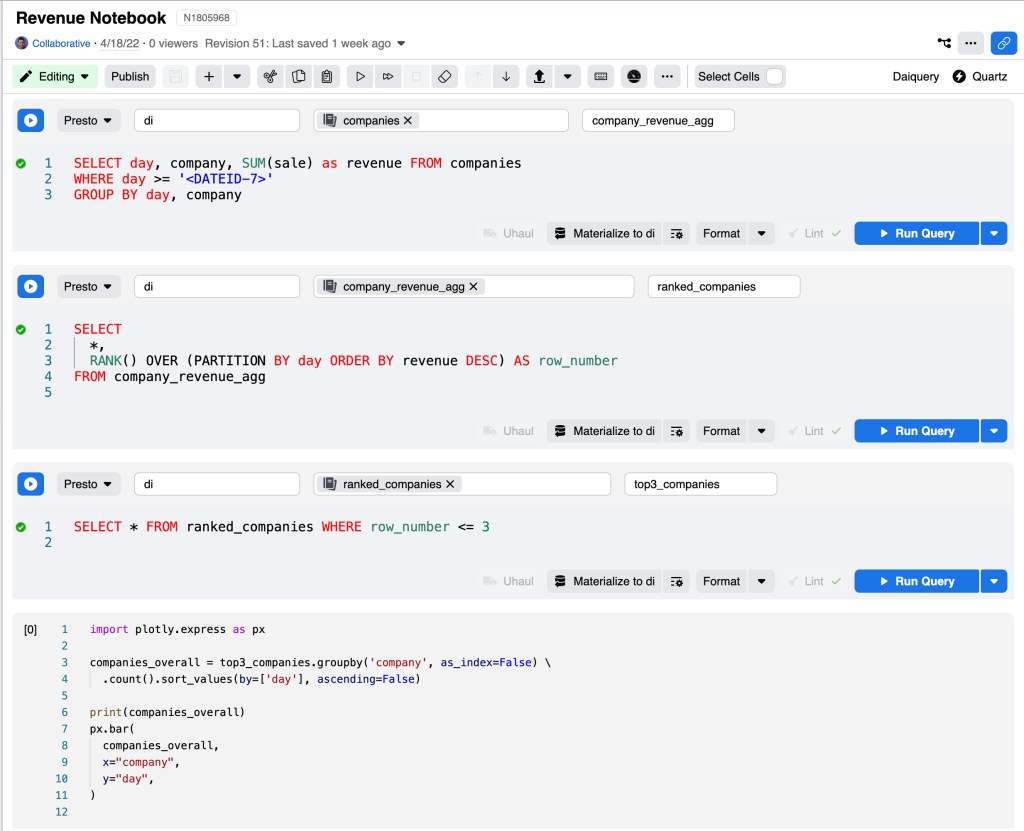
为了更好地处理也许是自然增长的查询,我们扩展了我们的SQL工具,Daiquery,以支持多个单元格,很像一个笔记本。每个单元格都可以有一个名字,并通过它们的名字引用其他单元格,就像它们是表一样。例如,假设我们想找到过去一周中每天收入最高的三家公司。
在第一个单元格中,我们按公司和日期汇总数据:
company_revenue_agg:
SELECT day, company, SUM(sale) as revenue FROM companies
WHERE day >= '<DATEID-7>'
GROUP BY day, company
在第二个单元格中,我们可以使用一个窗口函数为每一天内的每一家公司添加一个等级:
ranked_companies:
SELECT
*,
RANK() OVER (PARTITION BY ds ORDER BY hits DESC) AS row_number
FROM company_revenue_agg
最后,在第三个单元格,我们只选择前三名的排名:
top3_companies:
SELECT * FROM ranked_companies WHERE row_number <= 3
每个查询都很简单,可以独立运行以检查中间结果。当运行ranked_companies时,被发送到服务器的查询实际上是:
WITH
company_revenue_agg AS (
SELECT day, company, SUM(sale) as revenue FROM companies
WHERE day >= '<DATEID-7>'
GROUP BY day, company
)
SELECT *,
RANK() OVER (PARTITION BY day ORDER BY revenue DESC) AS row_number
FROM company_revenue_agg而当运行第三个单元格,top3_companies时,基础查询变成了:
WITH
company_revenue_agg AS (
SELECT day, company, SUM(sale) as revenue FROM companies
WHERE day >= '<DATEID-7>'
GROUP BY day, company
),
ranked_companies AS (
SELECT *,
RANK() OVER (PARTITION BY day ORDER BY revenue DESC) AS row_number
FROM company_revenue_agg
)
SELECT * FROM ranked_companies WHERE row_number <= 3不了解CTE的人可能最终会把这个查询组成一个嵌套查询,这将是更复杂和更难理解的。
值得注意的是,第二和第三单元都不需要前面单元的数据。他们的SQL被转化为一个独立的单元,分布式后端可以理解。这就避免了我们上面讨论的笔记本的可扩展性限制。
在打印/显示结果时,前端还默认在SQL中附加一个LIMIT 1000语句,所以如果company_revenue_agg的实际结果比较长,我们将只看到前1000行。当ranked_companies或top3_companies引用它时,这个限制并不适用。它只适用于请求输出的单元格的输出。
Python,可视化,和markdown
除了支持模块化的SQL之外,SQL Notebooks还支持基于UI的可视化。类似于 Vega,它对大多数常见的可视化需求都非常方便。它还支持用于内联文档的markdown单元。
SQL Notebooks 也支持沙盒式的 Python 代码。这个功能可以用于最后一公里的小数据处理,这在SQL中很难表达,但使用Pandas却很容易做到,并且可以用来利用自定义的可视化库,比如Plotly。
继续我们之前的SQL例子,如果我们想为上面得到的数据显示一个柱状图,我们可以直接运行这个Python单元:
import plotly.express as px
px.bar(
top3_companies,
x="day",
color="company",
y="hits",
barmode='group'
)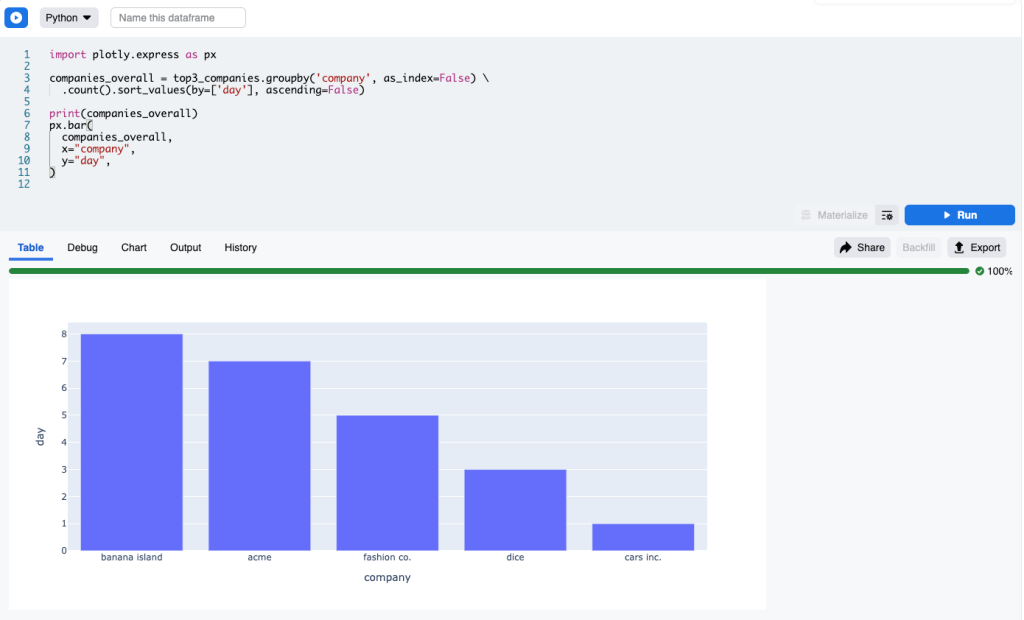
top3_companies被检测为这个片段的输入。因此,单元格top3_companies事先被运行,然后它的输出被作为Pandas数据帧提供。
注意,在Python中获取数据或做任何需要认证的操作都是不允许的。为了获取数据,Python单元需要依赖上游的SQL单元。这对解决安全问题至关重要,正如我们接下来要看到的。
###安全地共享输出
因为SQL的语法更有约束性,所以静态地确定一个给定的用户是否可以执行一个给定的查询是可行的。而对于像Python这样的动态语言来说,这几乎是不可能做到的。
因此,我们可以保存SQL查询的输出,但只有在用户可以首先运行SQL的情况下才使用它们。这意味着我们总是依靠表/列的ACL作为真相的来源,意外的数据泄露不会发生。
我们可以对Python单元应用同样的机制,因为我们不是在Python中查询数据。我们只需要检查Python单元所依赖的所有输入SQL是否可以由用户运行。如果是的话,使用缓存的输出来执行Python是安全的。
分享新鲜数据
因为我们有安全的方法来执行查询并对其快照进行访问控制,所以我们可以通过有计划的异步作业来更新快照,从而避免数据滞后。
SQL编辑
SQL笔记本也带来了Daiquery编辑器的最佳体验:自动完成,表格的元数据窗格(例如,列名、类型和样本行),SQL格式化,以及从单元格建立仪表板的能力。
##SQL 笔记本的下一步是什么?
必须指出的是,虽然SQL Notebooks有助于解决Python笔记本的一些常见问题,但它并不是一个全面的解决方案。它仍然需要用SQL来表达数据的获取,而且沙盒式的Python是有限制的。Bento/Jupyter笔记本仍然更适合于高级用例,如运行机器学习作业和通过其Python API快速与后端服务进行交互。
当我们在内部宣布这个工具时,有人注意到SQL Notebooks看起来与Bento/Jupyter笔记本多么相似。因此,我们一直在与Bento团队合作,将这两个工具合二为一,这样用户就可以在工具中进行权衡,而不是不得不选择和被锁定。我们还计划废除旧的Daiquery工具,而新的组合笔记本将成为访问分析数据的最终统一方式。