工业物联网(IIoT)在过去的几年里,从一个主要在石油和天然气行业进行试点的草根技术栈,如今发展到在制造、化工、公用事业、运输和能源行业广泛采用和生产使用。传统的物联网系统,如Scada、Historians甚至Hadoop,由于以下因素,无法提供大多数组织所需的大数据分析能力,无法对工业资产进行预测性优化。
| 挑战 | 所需能力 |
|---|---|
| 数据量显著增大且更加频繁 | 从物联网设备中可靠地采集和存储亚秒级颗粒读数的能力,且成本效益要高,每天的数据流为TB级。 |
| 数据处理需求更加复杂 | 符合ACID标准的数据处理–基于时间的窗口、聚合、枢轴、回填、移动,并能轻松地重新处理旧数据。 |
| 更多的用户角色希望访问数据 | 数据是一种开放的格式,易于与运营工程师、数据分析师、数据工程师和数据科学家共享,而不会形成孤岛。 |
| 决策需要可扩展的ML | 能够在细化的历史数据上快速、协作地训练预测模型,以做出智能的资产优化决策。 |
| 降低成本的要求比以往更高 | 低成本的按需管理平台,可随数据和工作负载独立扩展,不需要大量的前期资金。 |
企业正在转向类似Microsoft Azure这样的云计算平台,以利用它们所提供的可扩展的、支持IIoT的技术,使获取、处理、分析和服务时间序列数据源(如Historians和SCADA系统)变得简单。
- 在第1部分中,我们将讨论端到端技术堆栈以及Azure Databricks在现代物联网分析的工业应用的架构和设计中所扮演的角色
- 在第2部分中,我们将深入探讨部署现代IIoT分析技术,将现场设备的实时IIoT机对机数据摄入数据湖存储中,并直接在数据湖上进行复杂的时间序列处理
- 在第3部分中,我们将探讨利用工业物联网数据进行机器学习和分析
第一部分
案例 - 风力发电机优化
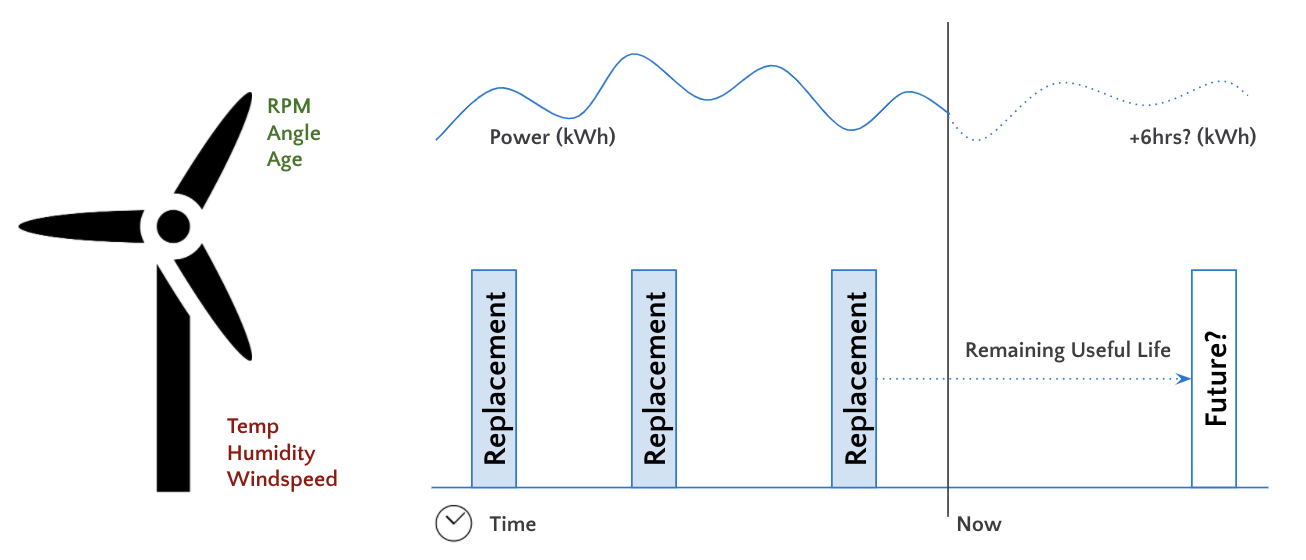
大多数IIoT分析项目都是为了最大限度地提高工业资产的短期利用率,同时最大限度地降低其长期维护成本。在本文中,我们重点关注一个假设的能源供应商,试图优化其风力发电机。最终目标是确定一组最佳的风机运行参数,以最大限度地提高每个风机的功率输出,同时最大限度地减少其故障时间。
该项目的最终交付物是:
一个自动的数据摄取和处理管道,将数据传送给所有终端用户
预测模型,在当前天气和运行条件下,估计每个风机的功率输出
预测模型,在当前天气和运行条件下,估计每个风机的剩余寿命
确定最佳运行条件的优化模型,以最大限度地提高功率输出,最大限度地降低维护成本,从而实现总利润的最大化
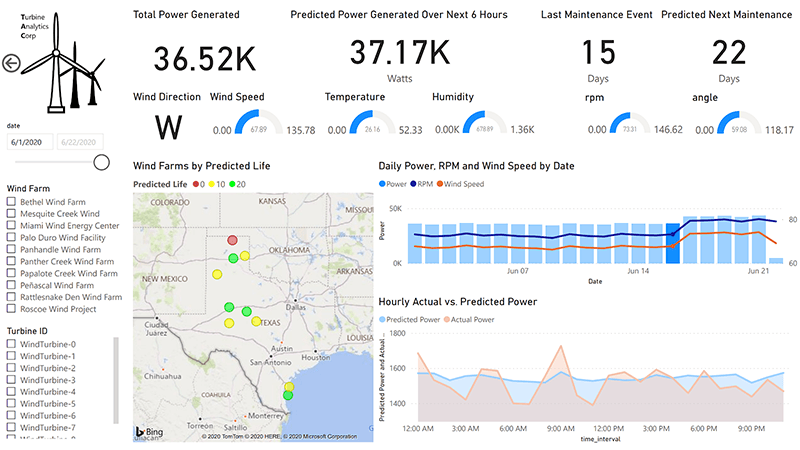
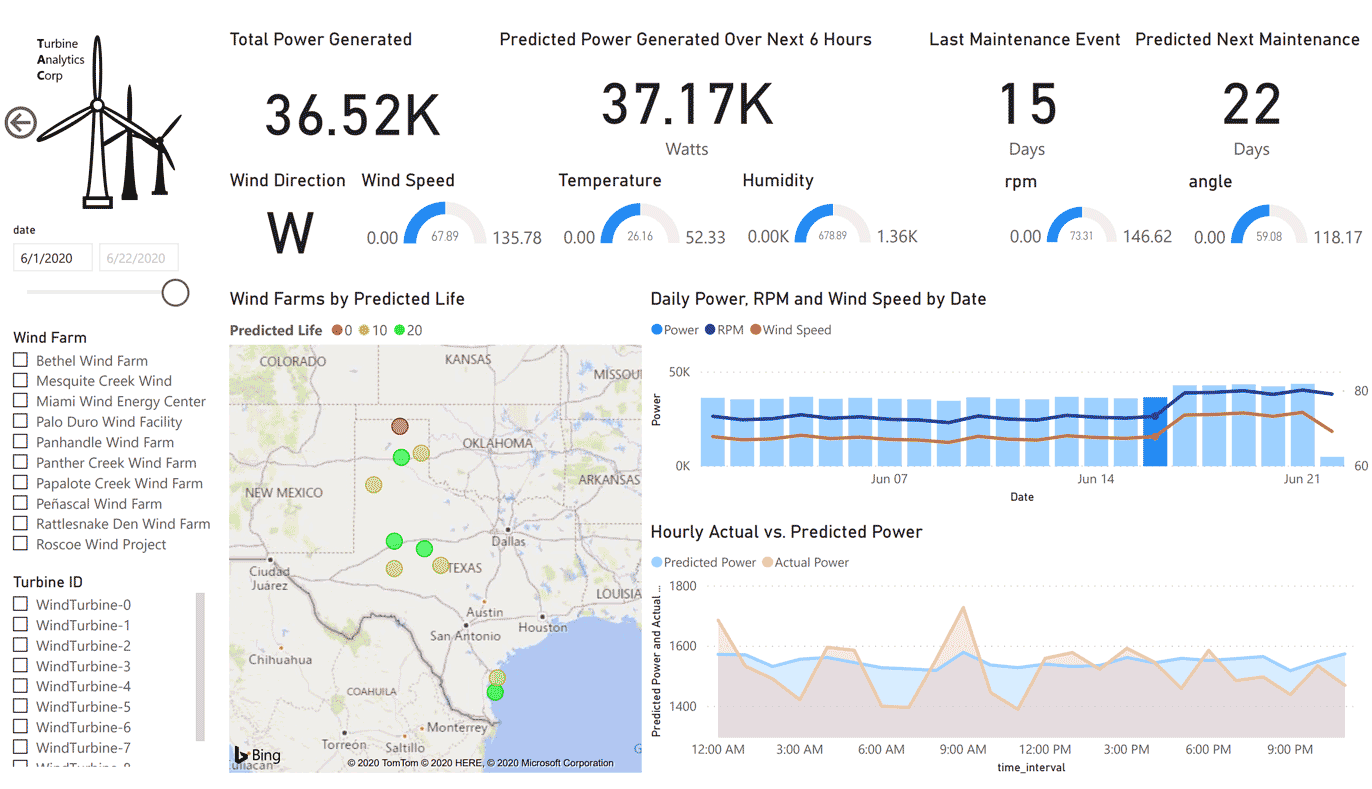
为业务团队提供了一个实时分析仪表盘,以可视化地显示其风电场的当前和未来状态,如下图所示:
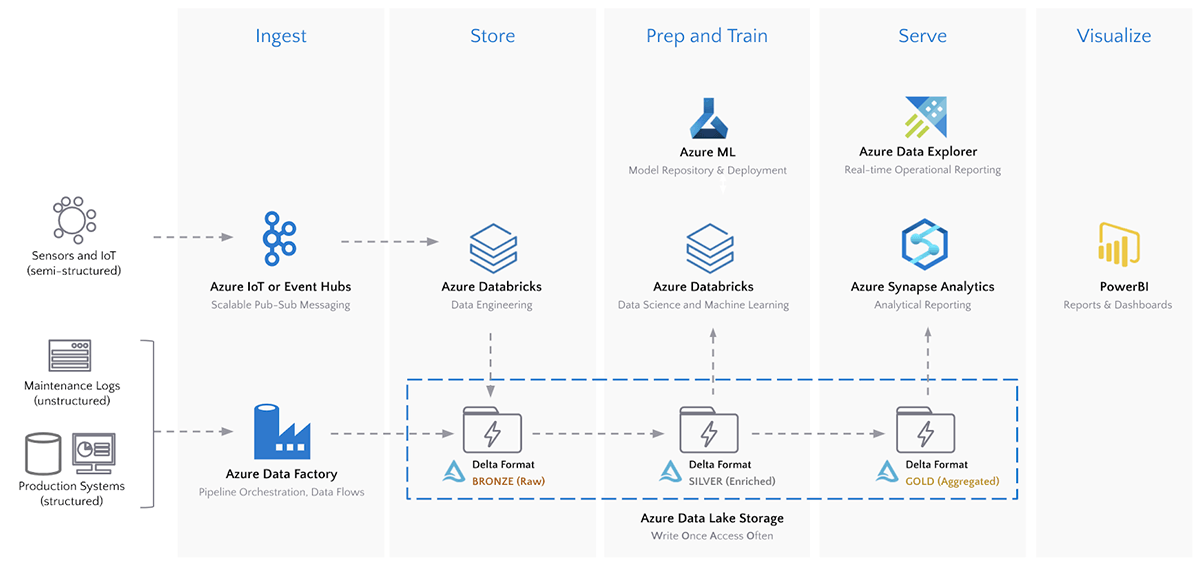
架构 - 获取、存储、准备、培训、服务、可视化
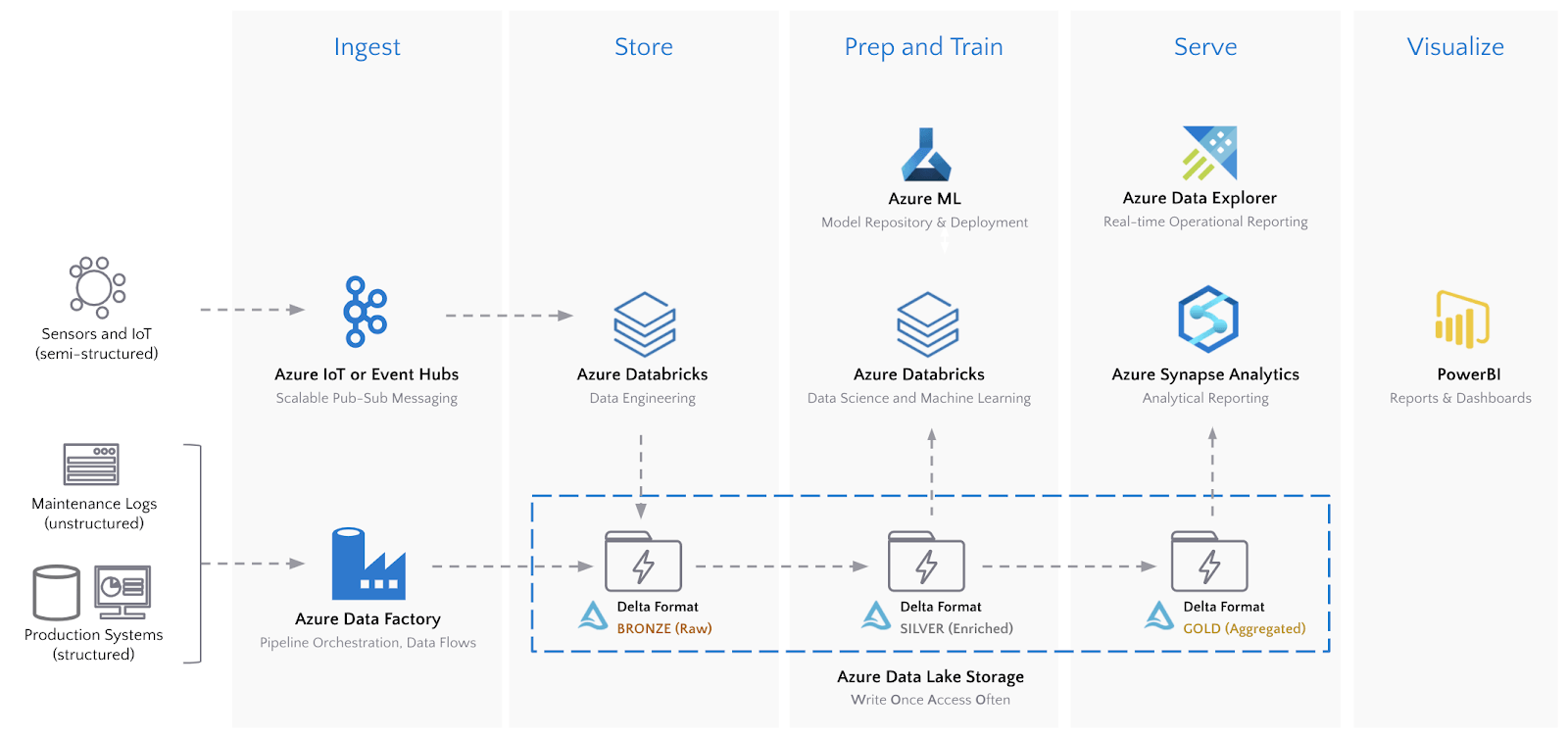
下面的架构说明了许多组织使用的现代最佳平台,该方案基于Microsoft Azure云为IIoT分析提供的所有功能。如果企业有独立的自研技术能力,类似的架构可以通过基于开源项目自主开发也可以灵活实现。

该架构的一个关键组件是 Azure 数据湖存储 (ADLS),它在 Azure 中实现了一次写入、多次访问的分析模式。然而,仅靠数据湖并不能解决时间序列流数据带来的现实世界挑战。砖厂的Delta存储格式在ADLS中存储的所有数据源上提供了一层弹性和性能。具体到时间序列数据,与ADLS上的其他存储格式相比,Delta具有以下优势。
| 所需能力 | ADLS Gen 2的其他格式 | ADLS Gen 2的Delta格式 |
|---|---|---|
| 流批一体化 | 数据湖经常与像CosmosDB这样的流式存储一起使用,从而形成一个复杂的架构。 | 符合ACID标准的事务使数据工程师能够在ADLS上执行流式摄取和历史上的批量加载到相同的位置。 |
| 模式执行和演变 | 数据湖不强制执行模式,要求所有数据都推送到关系型数据库中以保证可靠性。 | 模式是默认执行的。随着新的物联网设备被添加到数据流中,模式可以安全地演进,因此下游应用不会失败。 |
| 高效 Upserts | 数据湖不支持在线更新和合并,需要删除和插入整个分区才能执行更新。 | MERGE命令对于处理延迟的物联网读数、用于实时丰富的修改维度表或需要重新处理数据的情况非常有效。 |
| 文件压缩 | 将时间序列数据串流到数据湖中,会产生数百甚至数千个微小的文件。 | Delta中的自动压缩功能可以优化文件大小,以提高吞吐量和并行性。 |
| 多维聚类 | 数据湖仅在分区上提供下推式过滤功能。 | 在时间戳或传感器ID等字段上对时间序列进行ZORDER,可以对这些列进行过滤和连接,比简单的分区技术快100倍。 |
总结
在第一部分,回顾了传统IIoT系统面临的一些不同挑战。并介绍了现代IIoT分析的用例和目标,分享了组织已经在大规模部署的可重复架构,并探讨了Delta格式对每个所需功能的好处。
在第二部分中,将把现场设备的实时IIoT数据摄入Azure,并直接在数据湖上进行复杂的时间序列处理。
第二部分
第一部分中,我们介绍了大数据用例和现代IIoT分析的目标,分享了企业用于大规模部署IIoT的实际可重复架构,并探讨了Delta格式对现代IIoT分析所需的每个数据湖功能的好处。我们再回顾一下架构图:
部署
我们使用Azure的Raspberry PI IoT模拟器来模拟实时的机器对机器传感器读数,并将其发送到Azure IoT Hub。
数据获取:Azure IoT Hub到数据湖
我们的部署将天气(风速和风向、温度、湿度)和风机远程信息(角度和转速)的传感器读数发送到 IoT 云计算中心。Azure Databricks 可以原生地将来自 IoT 集线器的数据直接流到 ADLS 上的 Delta 表中,并显示数据的输入与处理率。
# Read directly from IoT Hubs using the EventHubs library for Azure Databricks
iot_stream = (
spark.readStream.format("eventhubs") # Read from IoT Hubs directly
.options(**ehConf) # Use the Event-Hub-enabled connect string
.load() # Load the data
.withColumn('reading', F.from_json(F.col('body').cast('string'), schema)) # Extract the payload from the messages
.select('reading.*', F.to_date('reading.timestamp').alias('date')) # Create a "date" field for partitioning
)
# Split our IoT Hubs stream into separate streams and write them both into their own Delta locations
write_turbine_to_delta = (
iot_stream.filter('temperature is null') # Filter out turbine telemetry from other streams
.select('date','timestamp','deviceId','rpm','angle') # Extract the fields of interest
.writeStream.format('delta') # Write our stream to the Delta format
.partitionBy('date') # Partition our data by Date for performance
.option("checkpointLocation", ROOT_PATH + "/bronze/cp/turbine") # Checkpoint so we can restart streams gracefully
.start(ROOT_PATH + "/bronze/data/turbine_raw") # Stream the data into an ADLS Path
)Delta允许我们的IoT数据在IoT Hub采集后的几秒钟内被查询。
%sql
-- We can query the data directly from storage immediately as it streams into Delta
SELECT * FROM delta.`/tmp/iiot/bronze/data/turbine_raw` WHERE deviceid = 'WindTurbine-1'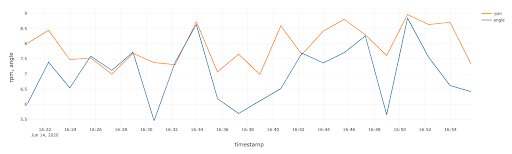
我们现在可以建立一个下游管道,丰富和聚合我们的IIoT应用数据,进行数据分析。
数据存储和处理:Azure Databricks和Delta Lake
Delta 支持采用多跳流水线方法进行数据工程,数据质量和聚合度随着流水线的流动而提高。我们的时间序列数据将流经以下青铜级、白银级和黄金级数据。(青铜-白银-黄金 可以理解为数据成熟度的不同阶段, Bronze (raw) to Silver (aggregated) to Gold (enriched))
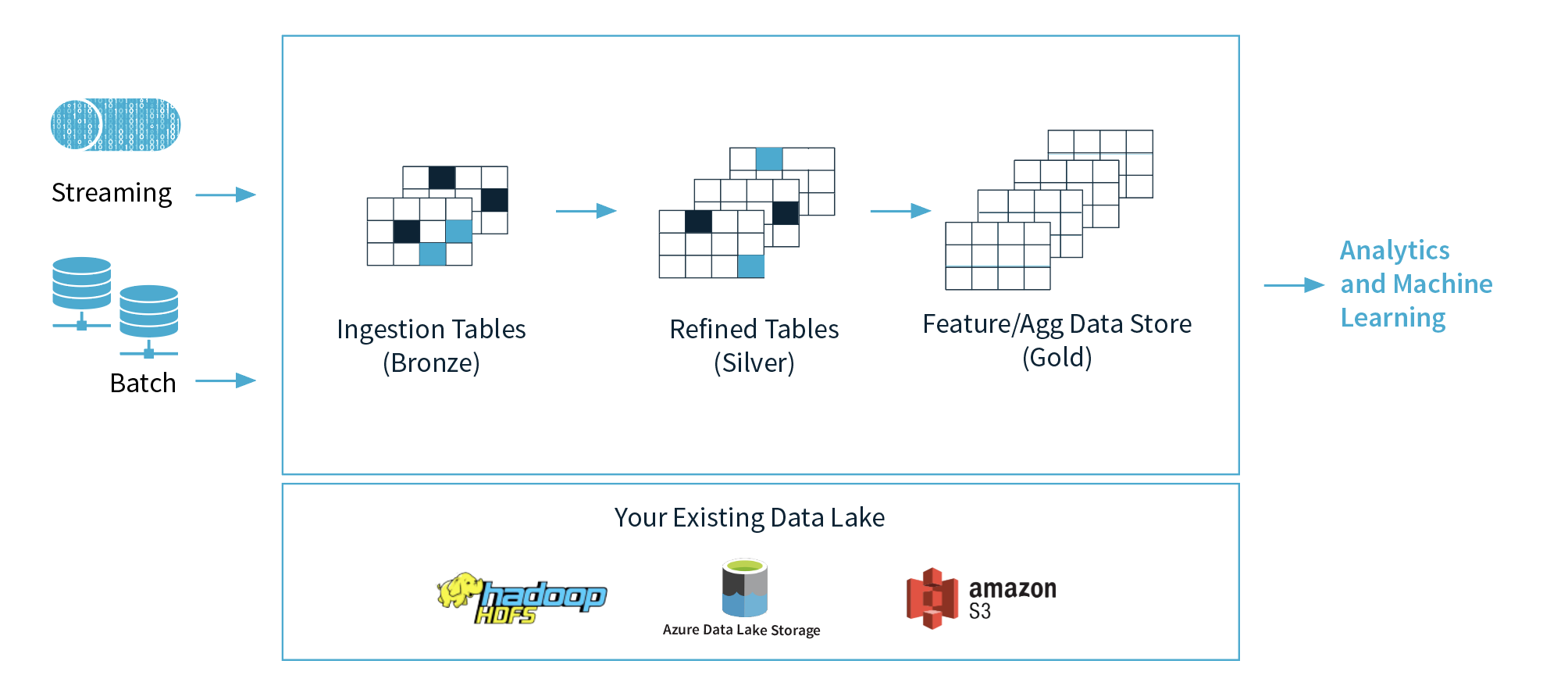
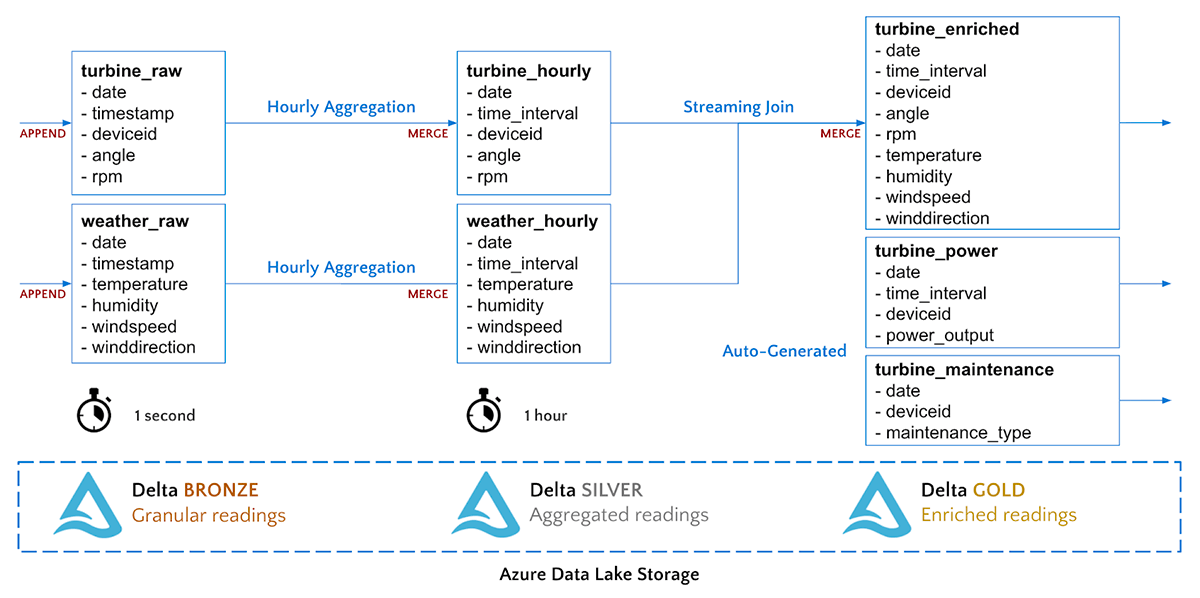
我们从青铜到白银的管道将简单地把我们的涡轮机传感器数据汇总到1小时间隔。我们将执行一个流式MERGE命令,将汇总的记录上传到银色的Delta表中。
# Create functions to merge turbine and weather data into their target Delta tables
def merge_records(incremental, target_path):
incremental.createOrReplaceTempView("incremental")
# MERGE consists of a target table, a source table (incremental),
# a join key to identify matches (deviceid, time_interval), and operations to perform
# (UPDATE, INSERT, DELETE) when a match occurs or not
incremental._jdf.sparkSession().sql(f"""
MERGE INTO turbine_hourly t
USING incremental i
ON i.date=t.date AND i.deviceId = t.deviceid AND i.time_interval = t.time_interval
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Perform the streaming merge into our data stream
turbine_stream = (
spark.readStream.format('delta').table('turbine_raw') # Read data as a stream from our source Delta table
.groupBy('deviceId','date',F.window('timestamp','1 hour')) # Aggregate readings to hourly intervals
.agg({"rpm":"avg","angle":"avg"})
.writeStream
.foreachBatch(merge_records) # Pass each micro-batch to a function
.outputMode("update") # Merge works with update mod
.start()
)我们从白银到黄金的管道将把这两条管道连接在一起,形成一个单一的表,用于每小时的天气和风机数据测量。
# Read streams from Delta Silver tables
turbine_hourly = spark.readStream.format('delta').option("ignoreChanges", True).table("turbine_hourly")
weather_hourly = spark.readStream.format('delta').option("ignoreChanges", True).table("weather_hourly")
# Perform a streaming join to enrich the data
turbine_enriched = turbine_hourly.join(weather_hourly, ['date','time_interval'])
# Perform a streaming merge into our Gold data stream
merge_gold_stream = (
turbine_enriched.writeStream
.foreachBatch(merge_records)
.start()
)我们可以立即查询我们的黄金级Delta表。

数据分析Notebook里还包含一个单元格,它将生成历史每小时功率读数和日常维护日志,用于模型训练。运行该单元格将:
在风机丰富表中回填一年的历史读数。
为power_output表中的每台风机生成历史功率读数。
在turbine_maintenance表中为每个风机生成历史维护日志。
现在,我们在Azure Data Lake上拥有丰富的就绪的人工智能(AI)数据,这些数据以高性能、可靠的格式提供给我们的数据科学建模,以优化资产利用率。
%sql
-- Query all 3 tables together
CREATE OR REPLACE VIEW gold_readings AS
SELECT r.*,
p.power,
m.maintenance as maintenance
FROM turbine_enriched r
JOIN turbine_power p ON (r.date=p.date AND r.time_interval=p.time_interval AND r.deviceid=p.deviceid)
LEFT JOIN turbine_maintenance m ON (r.date=m.date AND r.deviceid=m.deviceid);
SELECT * FROM gold_readings
我们的数据工程管道已经完成! 数据现在正从IoT Hubs流向青铜级(原始)到白银级(聚合)再到黄金级(丰富)。现在是时候对我们的数据进行一些分析了。
总结
综上所述,我们已经成功完成:
将现场设备的实时IIoT数据输入Azure中
直接在Data Lake上进行复杂的时间序列处理
在第三部分中,我们将探讨如何使用机器学习来最大限度地提高风力发电机的收益,同时最大限度地降低停机的机会成本。
第三部分
在第二部分关于Azure数据分析系列中,我们将现场设备的实时IIoT数据摄入Azure,并直接在Data Lake上进行复杂的时间序列处理。在第三部分中,我们将利用机器学习来进行预测性维护,并在最大限度地降低停机的机会成本的同时,使风力发电机的收益最大化,从而实现利润最大化。
我们的模型训练和可视化的最终结果将是一个Power BI报告,如下图所示:
再再回顾一下端到端架构,如下图所示:
机器学习:功率输出和剩余寿命优化
优化像风力发电机这样的工业资产的实用性、寿命和运营效率具有众多的收入和成本效益。我们在本文中探讨的现实挑战是在最大限度地提高风力发电机组的收益的同时,最大限度地降低停机的机会成本,从而使我们的净利润最大化。
净利润=发电收入-设备附加应变成本
如果我们将风机推到更高的转速,它将产生更多的能量,从而产生更多的收入。然而,风机所承受的额外压力将导致它更频繁地发生故障,从而引入成本。为了解决这个优化问题,我们将创建两个模型:
- 预测给定一组运行条件下风机的发电量
- 预测一组运行条件下风机的剩余寿命
然后,我们可以制作一条利润曲线,以确定最佳的运行条件,使电力收入最大化,同时使成本最小化。
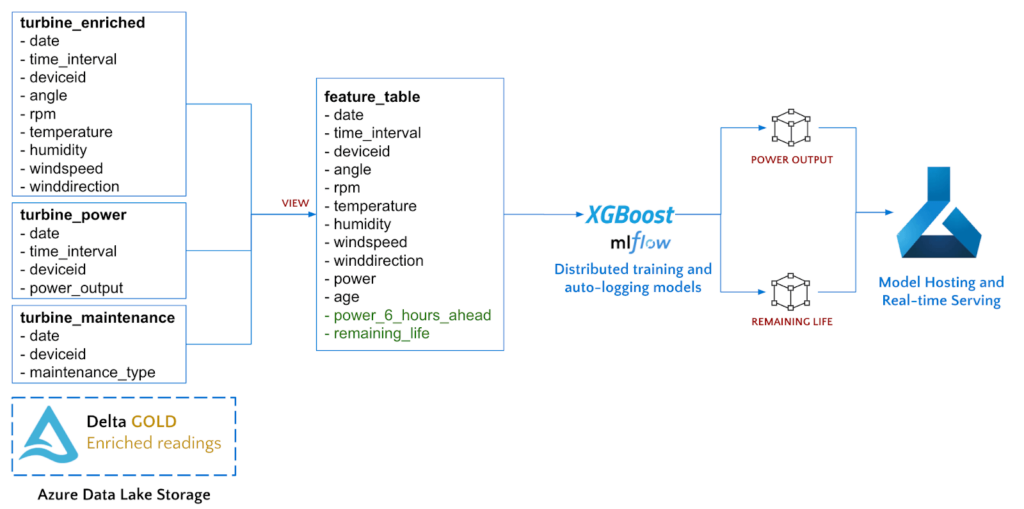
使用Azure Databricks与我们的Gold Delta表,我们将运用特征工程以提取感兴趣的领域,训练两个模型,最后将模型部署到Azure机器学习进行托管。
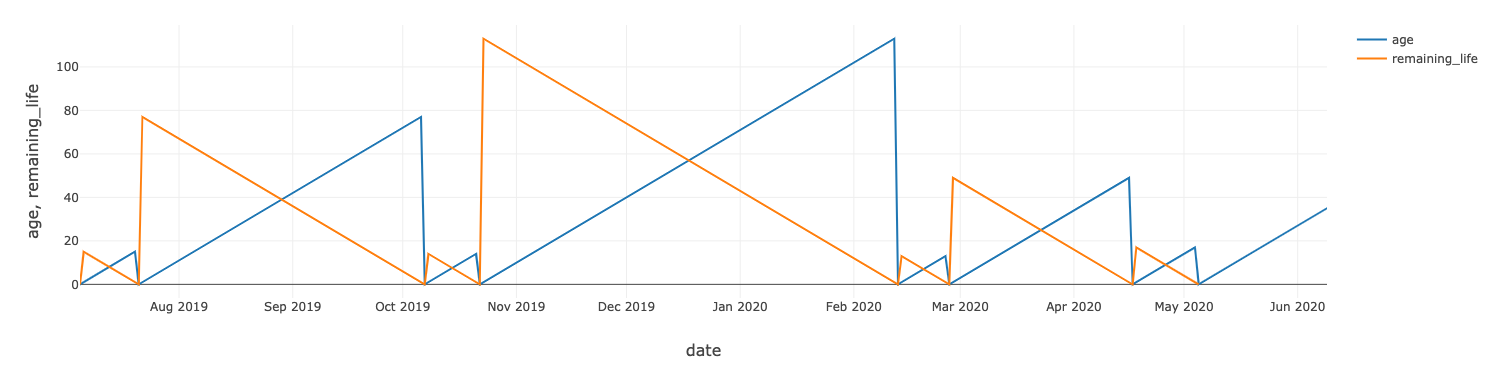
要计算每台风机的剩余使用寿命,我们可以使用我们的维护记录,该记录显示了每个资产的更换时间。
%sql
-- Calculate the age of each turbine and the remaining life in days
CREATE OR REPLACE VIEW turbine_age AS
WITH reading_dates AS (SELECT distinct date, deviceid FROM turbine_power),
maintenance_dates AS (
SELECT d.*, datediff(nm.date, d.date) as datediff_next, datediff(d.date, lm.date) as datediff_last
FROM reading_dates d LEFT JOIN turbine_maintenance nm ON (d.deviceid=nm.deviceid AND d.date<=nm.date)
LEFT JOIN turbine_maintenance lm ON (d.deviceid=lm.deviceid AND d.date>=lm.date ))
SELECT date, deviceid, min(datediff_last) AS age, min(datediff_next) AS remaining_life
FROM maintenance_dates
GROUP BY deviceid, date;为了预测6小时时间范围内的功率输出,我们使用Spark窗口函数计算时间序列移动。
CREATE OR REPLACE VIEW feature_table AS
SELECT r.*, age, remaining_life,
-- Calculate the power 6 hours ahead using Spark Windowing and build a feature_table to feed into our ML models
LEAD(power, 6, power) OVER (PARTITION BY r.deviceid ORDER BY time_interval) as power_6_hours_ahead
FROM gold_readings r
JOIN turbine_age a ON (r.date=a.date AND r.deviceid=a.deviceid)
WHERE r.date < CURRENT_DATE(); -- Only train on historical data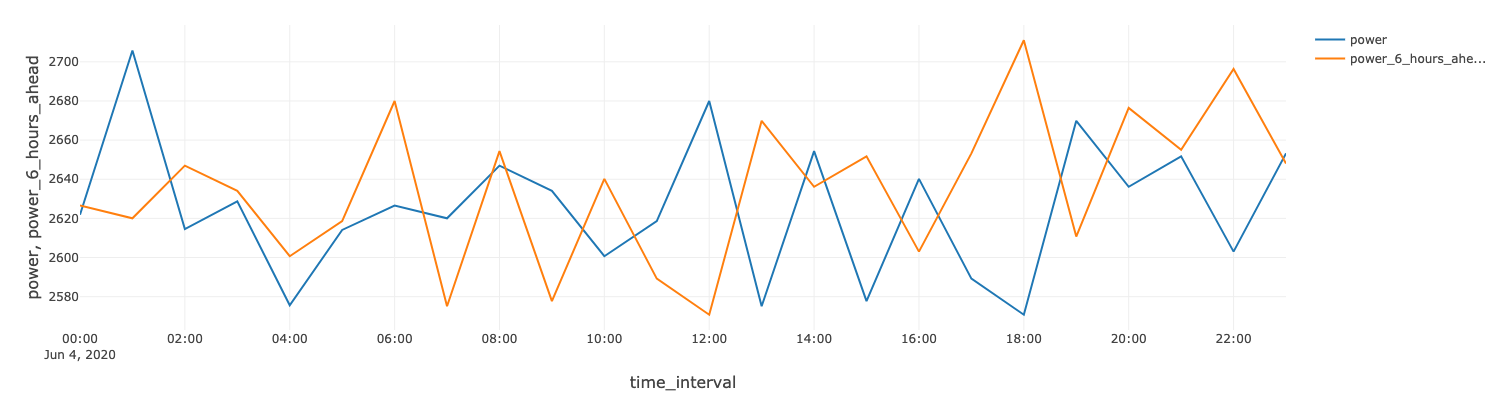
 通过对数据的分析可以发现风机的运行参数(转速和角度)以及天气状况和6小时后的发电量之间都有很强的相关性。
通过对数据的分析可以发现风机的运行参数(转速和角度)以及天气状况和6小时后的发电量之间都有很强的相关性。
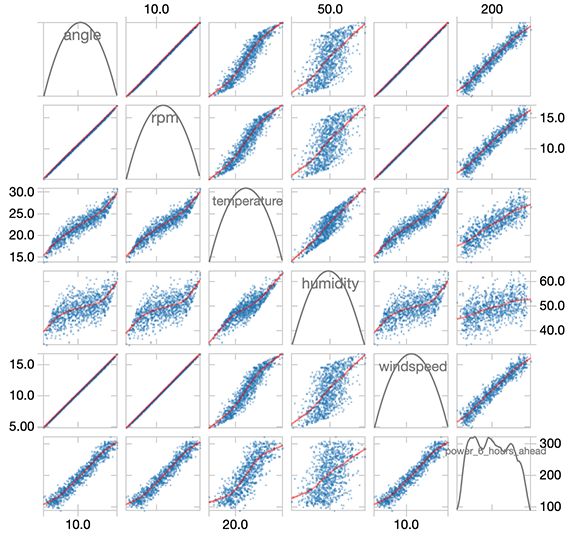
我们现在可以训练一个 XGBoost Regressor 模型,以使用我们的特征列(天气、传感器和功率读数)来预测我们的标签(提前六小时的功率读数)。我们可以使用Pandas UDF为每个风机并行训练一个模型,Pandas UDF将我们的XGBoost模型训练代码分发到Azure Databricks集群中的所有可用节点。
# Create a Spark Dataframe that contains the features and labels we need
feature_cols = ['angle','rpm','temperature','humidity','windspeed','power','age']
label_col = 'power_6_hours_ahead'
# Read in our feature table and select the columns of interest
feature_df = spark.table('feature_table')
# Create a Pandas UDF to train a XGBoost Regressor on each turbine's data
@pandas_udf(feature_df.schema, PandasUDFType.GROUPED_MAP)
def train_power_model(readings_pd):
mlflow.xgboost.autolog() # Auto-Log the XGB parameters, metrics, model and artifacts
with mlflow.start_run():
# Train an XGBRegressor on the data for this Turbine
alg = xgb.XGBRegressor()
train_dmatrix = xgb.DMatrix(data=readings_pd[feature_cols].astype('float'),label=readings_pd[label_col])
model = xgb.train(dtrain=train_dmatrix, evals=[(train_dmatrix, 'train')])
return readings_pd
# Run the Pandas UDF against our feature dataset
power_predictions = feature_df.groupBy('deviceid').apply(train_power_model)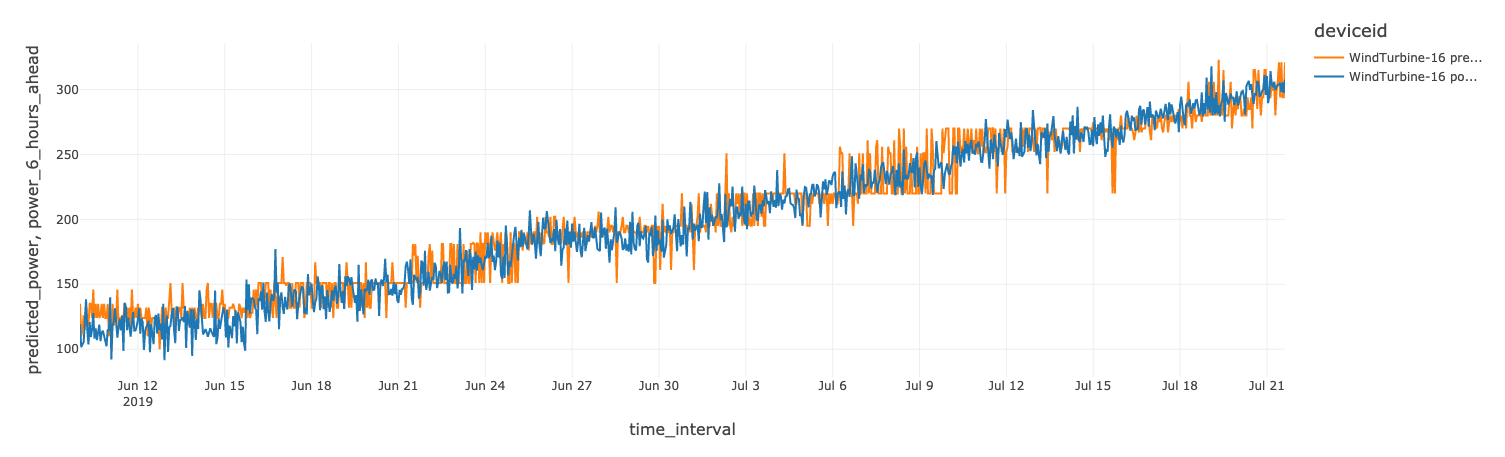
Azure Databricks 将通过托管的 MLflow 自动跟踪每个模型训练运行。对于 XGBoost Regression,MLflow 将跟踪任何一个参数、RMSE 指标等。例如,在设备id 是WindTurbine-18这台风机上预测功率的RMSE是45.79。
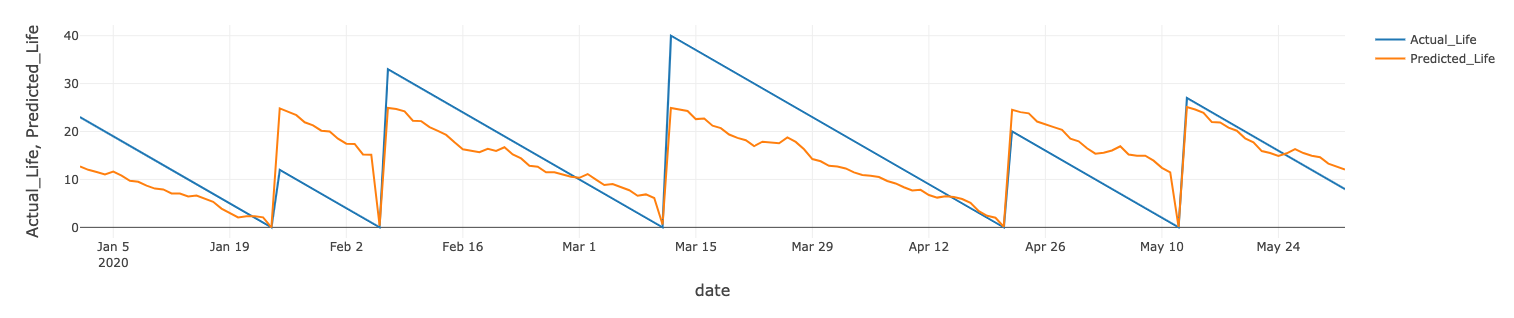
我们也对风机的剩余寿命进行类似的模型训练。其中一台风机的实际值与预测值对比如下图所示。
模型部署和托管
Azure Databricks与Azure机器学习集成,用于模型部署和评分。直接在Databricks内部使用Azure ML API,我们可以通过Azure ML为每个模型自动部署镜像,并将其托管在快速、可扩展的容器服务(ACI或AKS)中。
# Create a model image inside of AzureML
model_image, azure_model = mlflow.azureml.build_image(model_uri=path,
workspace=workspace,
model_name=model,
image_name=model,
description="XGBoost model to predict power output”
synchronous=False)
# Deploy a web service to host the model as a REST API
dev_webservice_deployment_config = AciWebservice.deploy_configuration()
dev_webservice = Webservice.deploy_from_image(name=dev_webservice_name,
image=model_image,
workspace=workspace)模型部署完毕后,就会显示在Azure ML studio里面,我们可以进行REST API调用,对数据进行交互式评估。
# Construct a payload to send with the request
payload = {
'angle':12,
'rpm':10,
'temperature':25,
'humidity':50,
'windspeed':10,
'power':200,
'age':10
}
def score_data(uri, payload):
rest_payload = json.dumps({"data": [list(payload.values())]})
response = requests.post(uri, data=rest_payload, headers={"Content-Type": "application/json"})
return json.loads(response.text)
print(f'Predicted power (in kwh) from model: {score_data(power_uri, payload)}')
print(f'Predicted remaining life (in days) from model: {score_data(life_uri, payload)}')现在功率优化和RUL模型都被部署为预测服务,我们可以利用这两个模型来优化每个风力发电机的净利润。假设每千瓦时1美元,年收入可以简单地通过将每小时预期功率乘以24小时和365天来计算。年成本可以通过将每天的收入乘以涡轮机一年内需要维护的次数(365天/剩余寿命)来计算。
我们只需对托管在Azure ML中的模型进行多次调用,就可以对各种运营参数进行迭代评估。通过可视化调整各种运行参数的预期利润成本,就可以确定最佳的转速以实现利润最大化。
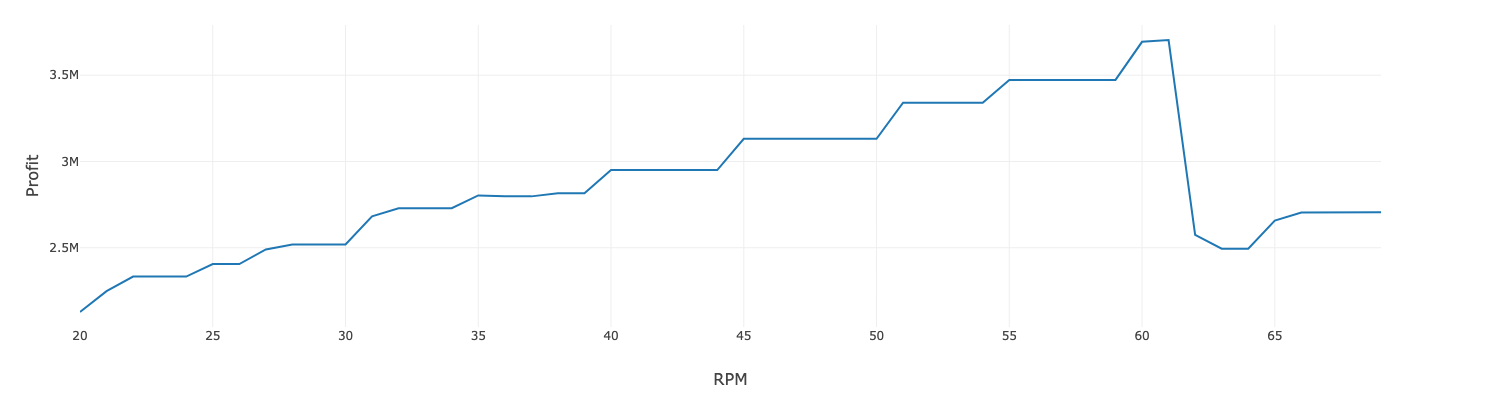
数据服务:Azure Data Explorer (ADX) 和Azure Synapse Analytics (ASA)
ADX中的业务报告
Azure Data Explorer (ADX) 提供对流式时间序列数据的实时操作分析。IIoT设备数据可以直接从IoT Hub流式传输到ADX中,也可以使用微软的Kusto Spark Connector从Azure Databricks推送,如下所示:
stream_to_adx = (
spark.readStream.format('delta').option('ignoreChanges',True).table('turbine_enriched')
.writeStream.format("com.microsoft.kusto.spark.datasink.KustoSinkProvider")
.option("kustoCluster",kustoOptions["kustoCluster"])
.option("kustoDatabase",kustoOptions["kustoDatabase"])
.option("kustoTable", kustoOptions["kustoTable"])
.option("kustoAadAppId",kustoOptions["kustoAadAppId"])
.option("kustoAadAppSecret",kustoOptions["kustoAadAppSecret"])
.option("kustoAadAuthorityID",kustoOptions["kustoAadAuthorityID"])
)接下来使用PowerBI连接到Kusto表,为风机工程师创建一个真正的、实时的、运行的仪表盘。Azure Data Explorer (ADX) 还包含原生的时间序列分析功能,如预测和异常检测。例如,下面的Kusto代码可以发现数据流中转速读数的异常点。
turbine_raw
| where rpm > 0
| make-series rpm_normal = avg(rpm) default=0 on todatetime(timestamp) in range(datetime(2020-06-30 00:00:00), datetime(2020-06-30 01:00:00), 10s)
| extend anomalies = series_decompose_anomalies(rpm_normal, 0.5)
| render anomalychart with(anomalycolumns=anomalies, title="RPM Anomalies")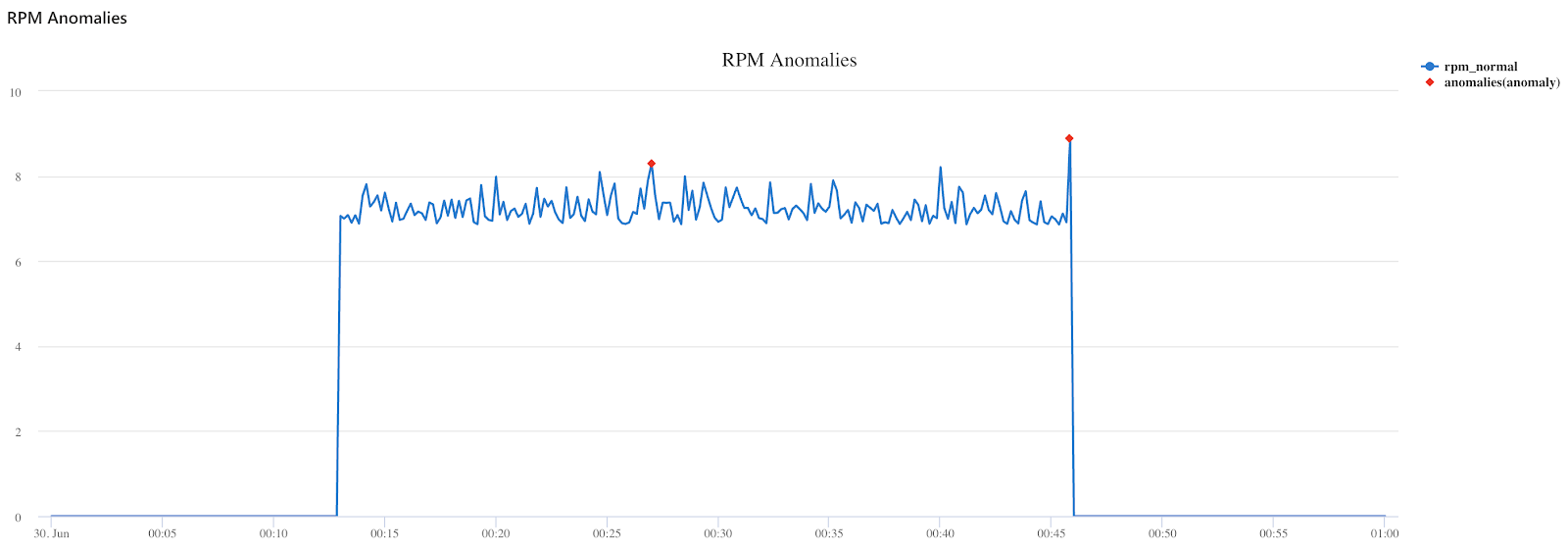
ASA中的分析报告
Azure Synapse Analytics (ASA)是Azure的下一代大数据数据仓库,它原生利用ADLS Gen 2并与Azure Databricks集成,以实现这些服务之间的无缝数据共享。
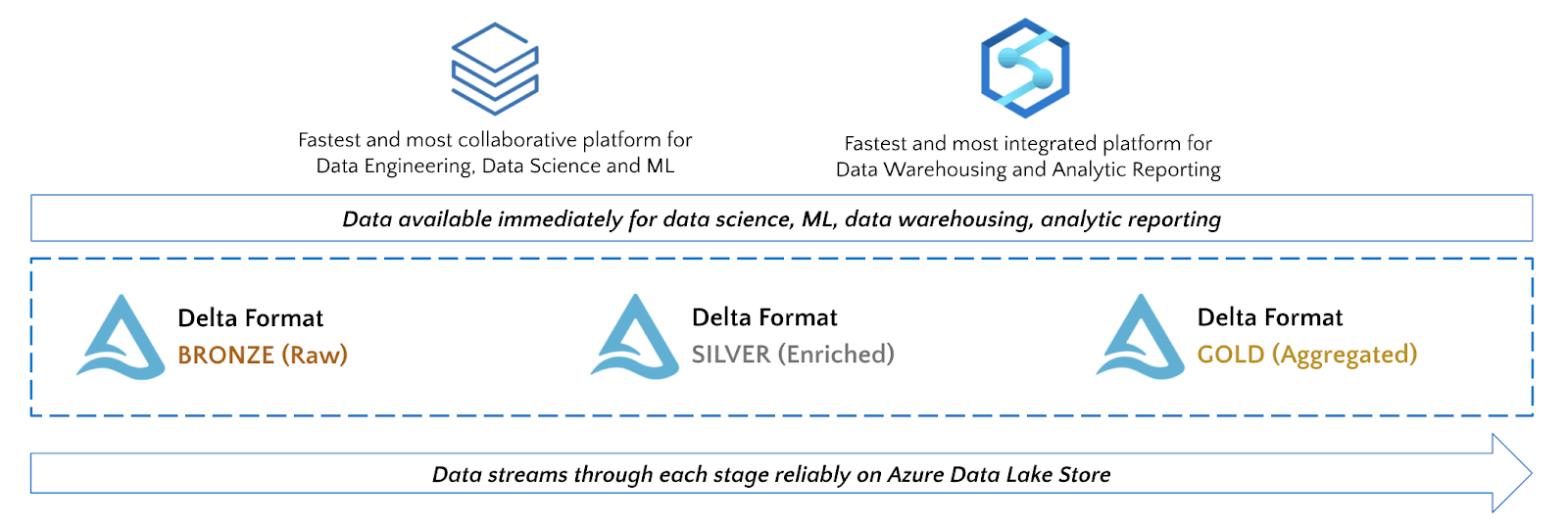
在利用Synapse和Azure Databricks的功能时,推荐的方式是根据团队的要求和访问数据的用户角色,使用最适合工作的工具。例如:
- 数据工程师和数据科学家倾向于使用 Azure Databricks获得Delta的性能优势,并拥有一个协作、丰富和灵活的工作空间
- 分析师将倾向于选择 Synapse进行低代码或基于数据仓库的 SQL 环境来摄取、处理和可视化数据
Azure Databricks的Synapse流式连接器使我们能够将(Gold级别)的读数直接流式传输到Synapse SQL池中进行开发数据报表。
spark.conf.set("spark.databricks.sqldw.writeSemantics", "copy") # Use COPY INTO for faster loads
write_to_synapse = (
spark.readStream.format('delta').option('ignoreChanges',True).table('turbine_enriched') # Read in Gold turbine readings
.writeStream.format("com.databricks.spark.sqldw") # Write to Synapse
.option("url",dbutils.secrets.get("iot","synapse_cs")) # SQL Pool JDBC (SQL Auth)
.option("tempDir", SYNAPSE_PATH) # Temporary ADLS path
.option("forwardSparkAzureStorageCredentials", "true")
.option("dbTable", "turbine_enriched") # Table in Synapse to write to
.option("checkpointLocation", CHECKPOINT_PATH+"synapse") # Streaming checkpoint
.start()
)也可以使用 Azure Data Factory 从 Delta 格式读取数据,并将其写入 Synapse SQL Pools。到这里数据已被清洗干净、处理妥当,可供数据分析师进行分析报告,可以针对实时数据以及 ML 模型的预测建立一个实时 PowerBI 仪表板。
总结
综上所述,我们已经成功完成:
- 将现场设备的实时IIoT数据输入Azure中
- 直接在Data Lake上进行复杂的时间序列处理
- 训练和部署ML模型,以优化风力发电机资产的使用
- 向工程师提供数据,用于业务报告,向数据分析师提供分析报告
整个方案基于Microsoft Azure来构建,当然通过AWS&阿里云也可以实现,因为Delta Lake(砖厂精品)是整个方案大数据技术的关键,它将一切联系在一起。ADLS上的Delta提供了可靠的流式数据管道和对海量时间序列数据的高性能数据科学计算和分析查询。最后,它赋能组织能够真正采用Lakehouse模式,将最佳的Azure技术组件引入一次写入、多次访问的数据存储中。